我們已經對純文字的 RAG 框架很熟悉了,當 AI 不知道答案時,它會去查詢資料、閱讀文件,然後生成回答。但當我們讓 AI 同時看圖片、聽聲音、讀文件時,整個系統的複雜度就提升了。
因為檢索的單位、上下文的結構,甚至查什麼才算相關都變得更加立體。這篇文章想跟大家分享如何設計能夠理解、查找並整合不同模態資訊的 RAG 系統與代理。
傳統的文字型 RAG,運作流程可以簡化為三個步驟,這個機制在處理文件、常見問答集或技術文檔時非常有效:
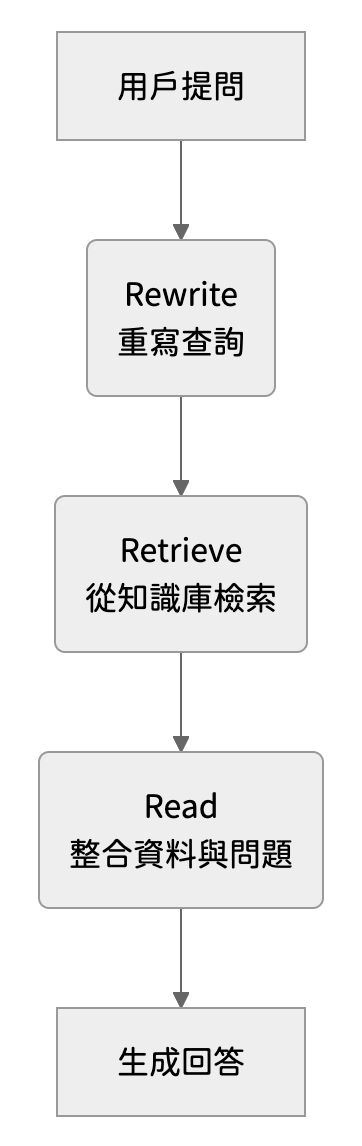
然而,當輸入的資訊來源從單一的文字擴展到圖片、音訊或影片時,原有的設計就不太夠用了,因為模型面對的不再只是文字知識庫,而是一個由多元資料構成的複雜環境,可能包含:
更重要的是這些模態之間存在著語義上的交叉連結。用戶的問題可能跨越多個模態,例如:「根據這張產品圖與最新的使用者評論,這款設計在實用性上有改善嗎?」
要回答這類問題,AI 系統必須具備多模態的檢索與生成能力,才能夠理解並整合不同來源的資訊。
多模態 RAG 在傳統 RAG 的基礎上,對每個階段都進行了擴展,以應對不同資料類型的挑戰。
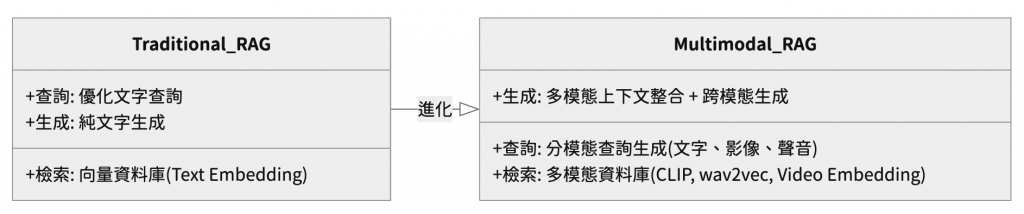
從單模態進化到多模態,帶來了幾個關鍵的工程問題:
因此,多模態 RAG 的工程重點在於,如何將這些異質的模態轉譯成可比較、可檢索、可被大型語言模型理解的統一語義單位。
在多模態系統中,檢索不再是單向的以文找文,使用者可以根據手邊的資料類型,靈活地查找另一種模態的相關資訊,這就是跨模態檢索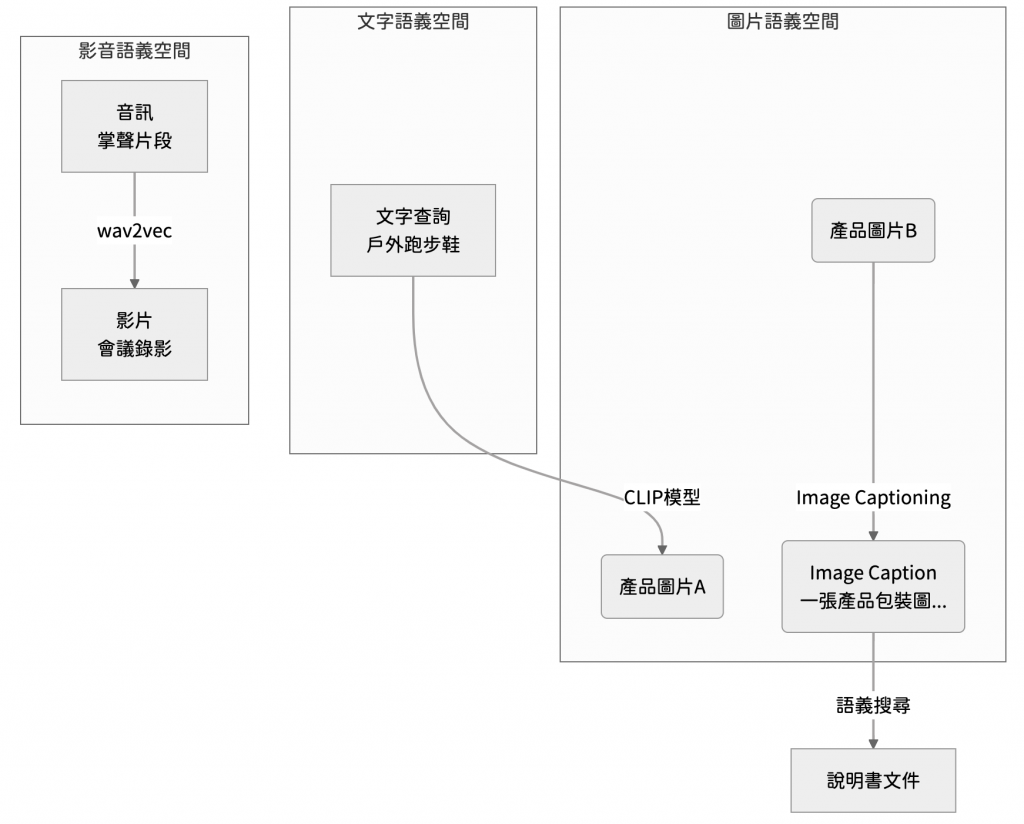
使用者輸入「找出所有提到戶外跑步鞋的產品照片」,AI 會使用 CLIP 這類模型,將文字與圖片轉換到相同的語義空間,再透過餘弦相似度計算,找出語義最接近的圖像。
使用者輸入「這張產品包裝圖的說明書是哪一份?」,系統會先對圖片生成文字描述,例如「一個白色的產品包裝盒」,再以這段描述作為文字查詢,進行語義搜尋並返回對應的文件
使用者輸入「找出所有包含掌聲片段的會議錄影」,AI 利用 wav2vec 或 AudioCLIP 等模型將音訊片段嵌入成向量,再與影片音軌的嵌入向量進行匹配,找出最相關的影片片段
但檢索到相關資料只是第一步,我們的重點是如何在生成階段有效的整合不同模態的上下文,讓模型真正理解這些資訊,以下是三種常見的方法:
先讓模型為每個模態的資料生成一段簡短的摘要,然後再將這些摘要進行語義融合。這種方法可以有效降低 Token 成本,同時保留各模態的核心資訊
範例輸入
[Image Summary]: 圖中顯示一名跑者穿著紅色的鞋子在戶外小徑上
[Text Summary]: 文件提到該鞋款主打輕量與透氣性
[Audio Summary]: 廣告配樂的節奏快速且充滿活力
任務
請整合這三種摘要,撰寫一句具有行銷感的口號
當不同模態的資料可靠性或重要性有顯著差異時,可以透過加權的方式來引導模型,我們可以在系統提示詞指定權重:「如果文字描述與圖片內容發生矛盾,請優先依據圖片的內容進行判斷」,也可以使用 Embedding 加權平均,這個是透過數學公式給不同模態的嵌入向量不同的權重
以 JSON 或類似的結構化格式來包裝多模態資訊,明確區分每個資訊的來源與用途。這不僅方便模型解析,也有助於它在推理階段保持邏輯的一致性。
{
"image_context": "一雙紅黑配色的跑步鞋,背景是戶外山景",
"text_context": "產品規格強調其優越的透氣性與防滑功能",
"audio_context": "廣告背景音樂為輕快配樂,節奏明快",
"task": "請為這款產品生成適合發佈在社群貼文的文案"
}
多模態 RAG 提供了資訊檢索的基礎,但當它與代理結合時,AI 不再只是被動回答問題,而是能主動規劃、調用工具,並完成指定的任務
在經典的 ReAct (Reason + Act) 框架中,代理的思考流程是:思考 → 行動 → 觀察 → 再思考。在多模態的場景中,我們可以為這個循環加入第三個維度:Perceive (感知)。
加入感知後,代理必須可以觀察圖片、影片或聲音,並將這些非文字的感知轉化為內部可用的語義描述,再進行下一步的思考與行動。
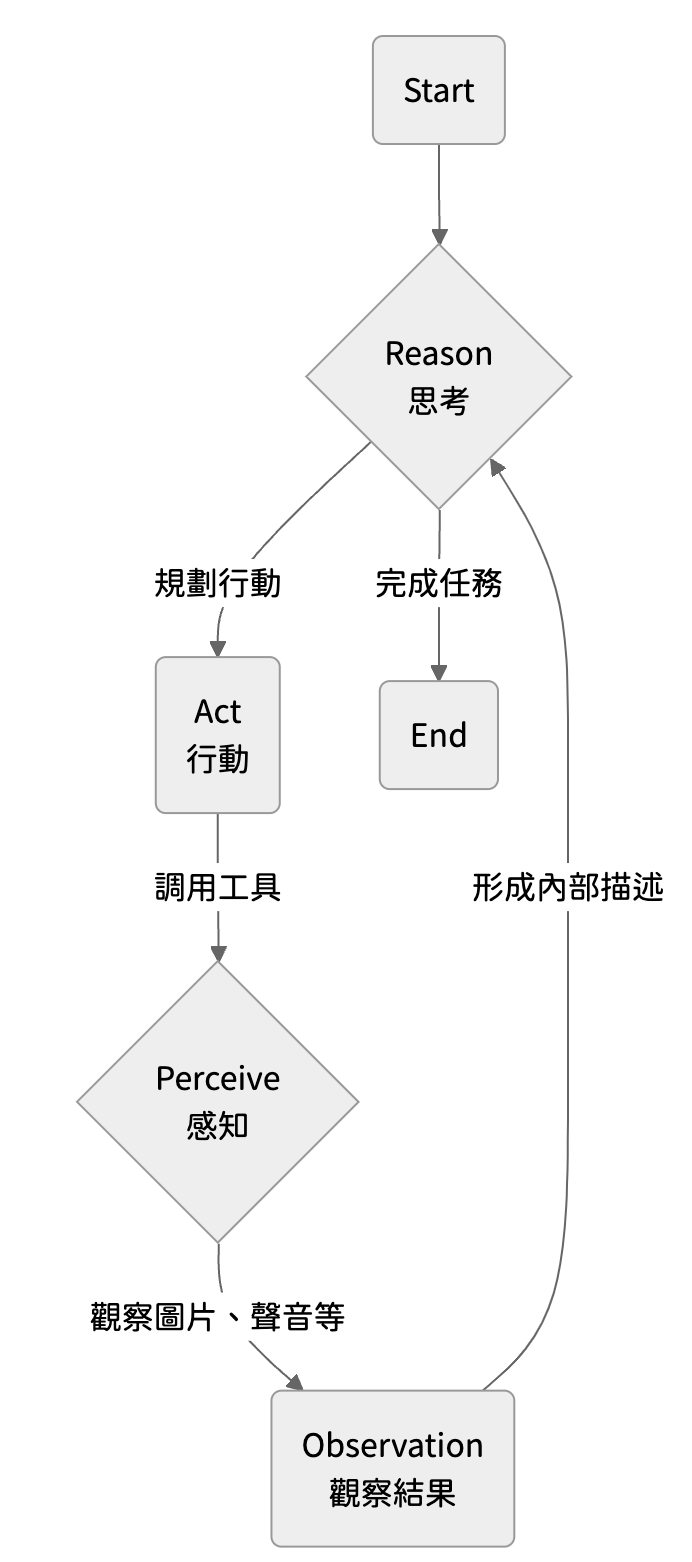
以下是一個代理執行思考的流程範例:
像這樣的多模態代理,除了檢索資訊外,還能像人類一樣認真思考:先看、先想,再說
假設我們要打造一個產品競爭分析助理,它能夠根據圖片、技術規格、社群聲量與市場報告,自動產出一份深入的洞察報告
預期系統會輸入以下資料:
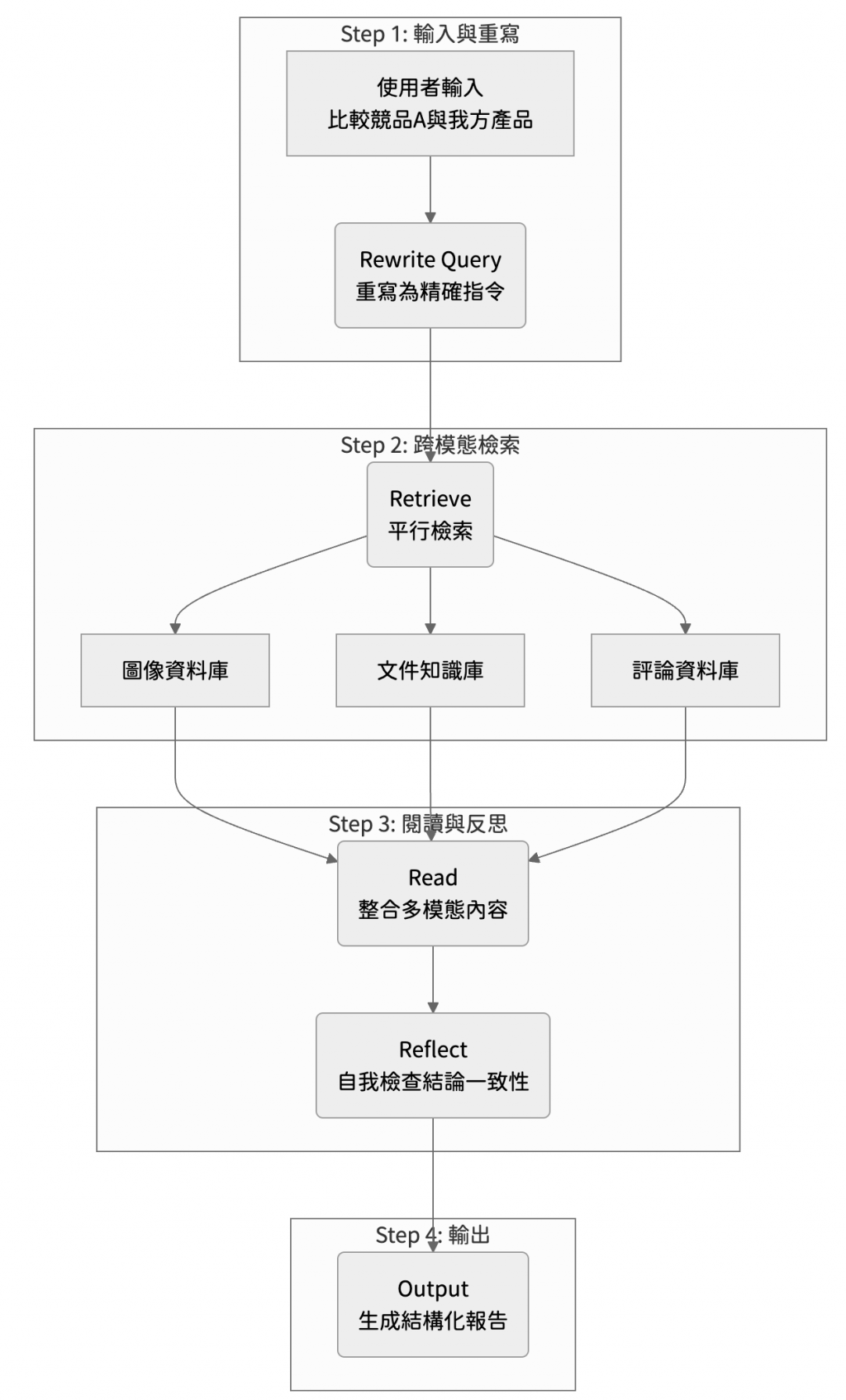
你是一位市場分析助理。
以下是關於競爭對手的多模態資料:
[Image A]: 競品外觀照片 (顯示其為灰色鋁合金材質)
[Doc B]: 技術報告摘要 (內容提到採用了新型的散熱結構)
[User Reviews]: 使用者評論中普遍強調「外觀高級但長時間使用容易發燙」
[Task]:
請整合以上所有資料,輸出一份包含三欄的分析報告:
- 外觀特徵
- 技術差異
- 使用者感受
請以 Markdown 表格格式呈現。
多模態 RAG 與代理的出現,讓 AI 從一問一答的知識+,變成一個能感知並行動的系統,在這個過程中,上下文工程扮演著非常重要的角色。它負責定義資料的結構、模態的邊界、融合的邏輯以及系統的反饋迴路。
以上有任何問題歡迎留言詢問


 iThome鐵人賽
iThome鐵人賽